There are lots of labeled data sets relevant to conservation that are not on LILA, of course, and rather than copying them all to LILA, this pagetracks other data sets we know about. This page complements the list of LILA datasets; the union of these two list is every conservation-related labeled dataset we’re aware of.
A few boundaries we draw around this list:
- This page is intended to track data sets that are nearly “machine-learning-ready”, i.e. an interesting set of labels that’s more or less attached to an interesting set of images/documents/etc. We are not tracking, for example, large repositories of unlabeled data.
- We are also not tracking private data repositories; roughly, if access requires anything more than filling out a form that’s almost auto-approved, it doesn’t go on this list.
- This page is not intended to track labeled geospatial data, even though many labeled geospatial datasets are critical for conservation. We do try to track other lists of labeled geospatial data in the “other lists of data sets” section at the end of this page.
If you know of data sets not on this list, or if you own one of these data sets but can no longer maintain it and would like to transfer it over to LILA, email us!
Table of contents
Image data sets (terrestrial wild animals) (ground-based sensors)
Image data sets (terrestrial wild animals) (aerial/drone)
Image data sets (domestic animals)
Image data sets (marine/freshwater)
…where marine life looks like ![]()
…where marine life is more nuanced
Image data sets (plants)
Image data sets (geospatial)
Image data sets (other)
Acoustic data sets
Competitions
Other lists of data sets
Terrestrial wild animal images (ground-based sensors)
Also see the list of competitions related to terrestrial animal images.
iNaturalist competition data (animal photos)

The iNaturalist competition provides around 500k labeled handheld-camera photos of around 8k species, varying a bit from year to year. Data originate from iNaturalist, a citizen-science platform for wildlife observation.

Around 48k images of 400 species of birds, with gender and age labels in many cases.
Caltech-UCSD birds (bird photos)

Caltech-UCSD Birds 200 (CUB-200) is an image dataset with photos of 200 bird species (mostly North American), including species labels, bounding boxes, and coarse segmentation masks.
Animals with attributes (animal photos)

37322 images of 50 animals classes with pre-extracted feature representations for each image.
Carrizo Camera Traps (camera traps)

100k camera trap images from California
Denison University Camera Trap Data (unlabeled camera traps)

~200 camera trap images from Denison University Biological Reserve (unlabeled)
MammalWeb OSF Data (camera traps)

~35k camera trap images from MammalWeb, with species labels
Penguin Counting in the Wild (camera trap photos with keypoints)

73,802 images taken by 15 different cameras from the Penguin Watch project, including keypoints indicating penguin locations within each image. Also available here in .mat and .json formats.
apic.ai bee poses (annotated bee images)
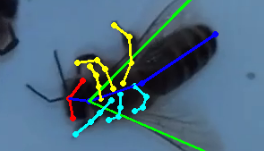
~200 images of bees with keypoint annotations
Arribada Human-Wildlife Conflict (annotated elephant images)

~76k thermal images of elephants, humans, and goats
Chimpanzee Faces in the Wild (individual ID)

Around 80 labeled examples each from around 25 individual chimps, with individual identifications.
Wildlife Image and Localization Dataset (species and bounding box labels)

Around 6k handheld-camera images and around 12k bounding boxes for 28 species.
Plittersdorf dataset (stereo camera trap images)

221 stereo camera trap videos of deer, with instance masks
PolarBearVidID (polar bear videos w/individual ID)

1431 video sequences of 13 individual captive polar bears
ANTS: ant detection and tracking (ants w/boxes)

~5k frames of ants with boxes
DSAIL-Porini: Annotated camera trap images … in Kenya (camera trap images)

8524 images of grazing animals in Kenya from custom camera traps
Karioi Predator Camera Trap (camera trap crops)

~6k 224×224 crops from camera trap images in New Zealand
Object detection of insects (boxes on insects)

~30k boxes on nine taxa of insects
BIOSCAN-1M (lab images of insects)

>1M lab images of insects with species labels
MEWC Case Study (camera trap crops)

50k cropped camera trap images from Tasmania
Marburg Camera Traps (camera trap images w/boxes)

~2100 images of European mammals and birds w/boxes
PanAf20K (ape videos w/behavior)

20k videos of apes with behavioral labels, 500 videos with boxes
Wild Animals Facing Extinction (boxes on handheld camera images)

7634 handheld-camera images of African mammals with boxes
Florida Wildlife Camera Trap Dataset

105k camera trap images from Florida with species-level labels

~3.5k images of footprints from 18 species

~25k total frames in 58 sequences of boxes with object IDs

~60k cropped camera trap images from 15 species, intended for OOD image identification

~4k camera trap images of urban wildlife from South Korea (paper)
Camera trap images of toads, lizards, and snakes

~6400 images from downward-facing cameras, containing toads/lizards/snakes
Amsterdamse Waterleidingduinen pilots (camera traps)

~50k camera trap images from the Netherlands
Camera trap images from Amsterdamse Waterleidingduinen

~48k labeled camera trap images from the Netherlands, divided into three GBIF datasets (1,2,3)
AMI: Insect Identification in the Wild

2.5M insect images curated from GBIF and 3k novel insect camera trap images (paper)
AP-10K: A Benchmark for Animal Pose Estimation in the Wild

~10k images with pose keypoints and background categories
Human vs. machine: detecting wildlife in camera trap images

~6k camera trap images from open arctic plains with image-level levels
Meerkat Behaviour Recognition Dataset

~850k frames in 20 videos of captive meerkats with behavioral annotations

10k videos and 28k stills with behavioral, box, and/or pose annotations

~1.4k videos of pandas with behavioral annotations

~6k high-res ground-sourced images of dense bird flocks with point annotations

178 ground-level videos of wetland birds with boxes, species labels, and behavioral labels
3D-POP (3D Postures of Pigeons)

Several hundred thousand frames of pigeons with boxes, keypoints, and individual ID
Wild-MuPPET (multi-view posture of pigeons)

Keypoints on videos of foraging pigeons
MammAlps (video with behavior labels)

Camera trap videos with audio, behavioral labels, and segmentation maps
Speleomantes photographic dataset (salamander images)

O(thousands) of lab images of cave salamanders, with capture location and morphological information
Camera trap images of Eurasian Lynx in the Ukrainian Chernobyl Exclusion Zone, 2012-2018

O(thousands) of camera trap images of lynx
Camera trap images from the ECN Cairngorm long-term monitoring site, 2010-2022

O(hundreds) of camera trap images with species labels
Camera trap photographs from the Chernobyl Exclusion Zone, Ukraine (Jun – Nov 2020)

O(hundreds) of camera trap images with species labels
Camera trap photographs from the Chernobyl Exclusion Zone, Ukraine (Nov 2020 – Mar 2021)

~12k of camera trap images with species labels

~10k camera trap videos with segmentation masks

Videos of a variety of mammals with 12 behavioral labels

50 hours of video with coarse behavioral labels, 30k sequences with fine-grained labels, 33k frames with pose labels

RGB video and lidar of moving animals, with behavior labels
Terrestrial wild animal images (aerial/drone)
Also see this much more detailed list of datasets with annotated wildlife in drone/aerial images.
Also see the list of competitions related to terrestrial animal images.

Point and species annotations on aerial images of savanna
UAV-derived waterfowl thermal imagery dataset (thermal and RGB images)

Waterfowl annotated in thermal drone images
Drones count wildlife more accurately and precisely than humans (counts and drone images)

Counts of fake bird colonies in drone images
Counting animals in aerial images with a density map estimation model (penguins in aerial images)

Keypoint annotations on penguins in aerial images
The Aerial Elephant Dataset (aerial images)

>2k images containing >15k annotated elephants
Global Model of Bird Detection Dataset (birds in aerial images)

Images and around 250,000 keypoint annotations from 13 bird detection projects.
Aerial Photo Imagery from Fall Waterfowl Surveys (birds in aerial images)

~130k aerial images with keypoint annotations on birds.
A different packaging of the same dataset is hosted on LILA.
Drones and deep learning for seabird colonies (birds in drone images)

28 drone mosaics with ~40k annotations on penguins and albatrosses

~2000 boxes on cattle in aerial imagery
Large-scale, Semi-Automatic Inference of Animal Behavior from Monocular Videos

Oblique aerial videos of zebras with 162931 bounding boxes and behavioral labels (standing, grazing, etc.)

Drone images of ungulates and geladas with 40532 bounding boxes
Deep object detection for waterbird monitoring using aerial imagery

Drone images of seabirds with 23078 boxes
KABR: In-Situ Dataset for Kenyan Animal Behavior Recognition from Drone Videos

130366 drone videos, each following a single individual savanna ungulate, with behavior labels

~29k frames with boxes on zebras in UAV images, collected from Ol Pejeta Conservancy in Kenya

~8k frames with boxes on onagers, giraffe, zebra, and wild dogs in UAV images, collected at The Wilds Conservation Center in Ohio

~130k frames with boxes on giraffe and zebra in UAV image, collected at Mpala Research Center in Kenya
WAID: Wildlife Aerial Images from Drone

14,366 drone images with boxes on ungulates and seals
Identification of free-ranging mugger crocodiles (crocodiles in drone images)

Individual ID annotations on crocodiles in drone images
BuckTales (UAV footage of deer)

18.4k boxes, tracking IDs, and individual IDs on deer in UAV images
SAVMAP (UAV images of Namibian wildlife)

O(thousands) of annotations outlining wildlife in ~650 UAV images
BAMBI (UAV images of Austrian wildlife)

~5100 tracks with ~93k annotated keyframes for 10 species on 389 thermal/RGB videos
Nadir imagery in South African savanna

20,137 UAV images with boxes
Big Bird (segmentation labels on birds in UAV images)

49,490 bird annotations on 4,824 images
Domestic animals
Stanford Dogs (dog photos with bounding boxes)

Around 20k images of 120 dog breeds, with both class labels and bounding boxes. Conservation-related? Not exactly, but let’s face it, lots of us work on this kind of data because we like looking at pictures of animals.
Oxford Pets (pet photos with bounding boxes and masks)

Around 7500 images of pets in 37 classes, with class labels, bounding boxes, and segmentation masks. Again, maybe not squarely related to conservation or biology, but finding furry things with machine learning is finding furry things with machine learning, right?
Fresian Cattle 2015 (individual ID)

~350 images labels as ~50 individual cows
Cattle Noseprints for Individual ID
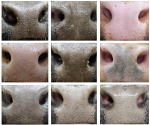
~5000 images of cattle muzzles with individual IDs

~10k images and ~300 videos of in-barn cattle with boxes and individual IDs

~3700 images of in-barn cattle with boxes and individual IDs
CherryChèvre (goats with bounding boxes)

6160 images of domestic goats from handheld or security-style cameras, with boxes

~260k individuals from 319 breeds
Poses for Equine Research Dataset

Motion capture data from horses (code)

Body part annotations on horses in ~8k video frames
Marine/freshwater images
Also see the list of competitions related to aquatic images, and the Awesome Fishies list of awesome fish datasets.
This section is broken into datasets where marine life looks like what a little kid thinks a fish looks like (you know, like ![]() ), and datasets with a more diverse concept of marine life.
), and datasets with a more diverse concept of marine life.
Marine/freshwater images (where fish look fishy)
Project Natick Underwater Video (marine species)

~1k images of fish w/bounding boxes

~3k images of out-of-water fish w/species labels and segmentation masks
Roboflow Fish Dataset (boxes on fish)

680 images of fish w/bounding boxes
Labeled Fishes in the Wild (boxes on fish)

~1k images of fish w/boxes, ~3k blanks
Fishnet.AI (images of fishing vessels)

~163k bounding boxes on ~35k images of fish and people on fishing vessels
Croatian Fish (cropped images of fish)

800 images of fish in 12 classes (description)
DeepFish (annotated fish images)

~40k images with a mix of classification, segmentation, and counting labels
Deep Vision Fish Dataset (segmented fish)

Segmented fish and associated empty backgrounds, intended for training data generation
BrackishMOT (annotated videos of fish)

98 videos of fish with tracking boxes (i.e., boxes with stable frame-to-frame IDs)
Visual Marine Animal Tracking (VMAT)

32 video sequences with bounding boxes on a variety of species

80k cropped fish images with 45k bounding boxes
VIAME FishTrack (BRUV images w/boxes)

Several thousand BRUV images with bounding boxes on fish and bait
F4K Detection and Tracking (videos with tracking points)

17 10-minute videos with tracking points
FishCLEF-2015 (videos with boxes)

14k boxes on fish in 20k images
WildFish (cropped images of fish from online sources)

54,459 images of fish in 1000 categories
Object detection of tropical freshwater fish in Australia (freshwater species)

~44k images of fish w/ ~83kbounding boxes

~7k labeled images of freshwater fish, generally not in the water, cropped close
Brook trout imagery for individual ID (fish w/ID)

435 images of brook trout with individual ID labels
AAU Zebrafish Re-Identification Dataset

~2200 images of zebrafish with individual IDs

Eight long stereo video sequences of zebrafish with boxes and keypoints

Boxes on 532,000 frames from 1,567 videos of salmon in two weirs

1500 images of fish (not in the water) with segmentation masks
Annotated underwater fish detection from pond environments

10,607 boxes on 586 images
Annotated luderick in Queensland

~9k segmentation masks on fish in seagrass meadows
SUIM (Segmentation of Underwater Imagery)

1500 underwater images with segmentation masks
Coralscapes (segmented coral scenes)

2075 underwater images with segmentation masks
NOAA Puget Sound Nearshore Fish (fish w/boxes)

~68k boxes on fish and crabs. (I don’t generally include LILA datasets on this page, but I’m breaking my own rule just this once, because I use this section as a de facto list of public fish-y-fish datasets.)
MIT Sea Grant River Herring (fish w/boxes)

~91k boxes on fish. (I don’t generally include LILA datasets on this page, but I’m breaking my own rule again, because I use this section as a de facto list of public fish-y-fish datasets.)
Newfoundland Marine Refuge Fish Classification Dataset (N-MARINE) (fish w/boxes)

~24k images of fish with ~24k boxes

~16k images of fish with boxes and/or masks

~35k boxes on ~4k images from a cabled observatory in the Mediterranean

~6k boxes on ~3k images from a BRUV in the North Atlantic
Marine/freshwater images (where marine life doesn’t exactly look fishy)

Point annotations on sea turtles in drone images
FathomNet (annotated images of ocean life/structures)
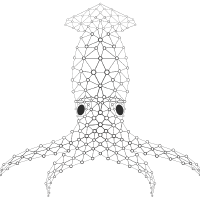
~70k labeled images representing a variety of marine entities

1011 dolphin fin images with individual IDs
Whales from Space (exactly what it says)

633 boxes on whales in satellite imagery
SMarTar-ID (Standardised Marine Taxon Reference Image Database) (ocean imagery)

Database of ocean species images, particularly cnidarians and sponges
Eagle rays images (boxes on rays)

~500 aerial images w/boxes on rays
Caltech Fish Counting (freshwater sonar)

>500k annotations on fish in sonar video
Underwater sonar surveys of mullet schools (home)

500 annotated sonar images
SealID (individual seal ID images)

Images of ringed seals with individual ID labels and segmentation masks
Deepdive (deep-sea ROV images)

~4k ROV images with deep-sea biota in 62 categories
Plants
Also see the list of competitions related to plant images.
Kahikatea dataset (segmented trees)

Aerial imagery from New Zealand in which Kahikatea trees have been masked
Tree species in Northern Australia (trees in UAV imagery)

2547 polygons on 36 Australian tree species
Urban Tree Detection Data (trees in aerial imagery)

Keypoints on ~40k trees in NAIP data.
The Auto Arborist Dataset (trees in street-level imagery)

>2M trees in street-level imagery annotated by genus
Oxford Flowers (flower photos)

Images of approximately 120 flower species, with between 40 and 250 images of each.
Pl@ntNet-300K (images of plants)

~300k labeled images of plants
Healthy vs. Diseased Leaf Image Dataset (images of leaves)

~4k images labeled w/species and disease status

100 images with 920 trees w/segmentation masks
NeonTreeEvaluation (trees in aerial and lidar surveys)

~3k bounding box annotations on RGB, hyperspectral, and lidar survey data
Pasadena Urban Trees (trees in aerial and street view photos)

Around 30k trees, imaged from aerial and street views, with location and species information.
FOR-instance (segmented trees in lidar)

1130 trees (with classes) manually segmented in airborne lidar data
Avo-AirDB (segmented trees in drone imagery)

986 drone images of avocado plantations with segmented individual trees
Image data sets (geospatial)
Also see the list of competitions related to geospatial images.
BigEarthNet (land cover, satellite)

>500k Sentinel images with patch-level land cover labels
EuroSAT (land cover, satellite)

>27k Sentinel images with patch-level land cover labels
Image data sets (other)

Segmentation labels and taxonomic identifiers for garbage.
DL for meteorological by-catch (weather in camera traps)

Camera trap images labeled according to weather conditions.
Bioacoustic data sets
Also see:
- The list on this page of competitions related to bioacoustic data
- Tessa Rhinehart’s fancy spreadsheet of bioacoustic datasets
- Justin Salamon’s list of bioacoustic data sets
- Céline Angonin’s datasets for bioacoustics page
Fully-Annotated Soundscape Recordings from the Northeastern United States

285 hour-long recordings with 50,760 bounding boxes on 81 bird species
Fully-Annotated Soundscape Recordings from the Western United States

33 hour-long recordings with 20,147 bounding boxes on 56 bird species
Fully-Annotated Soundscape Recordings from the Southwestern Amazon Basin

21 hour-long recordings with 14,798 bounding boxes on 132 bird species
Fully-Annotated Soundscape Recordings from the Sierra Nevada Mountains

100 10-minute recordings with 10,296 bounding boxes on 21 bird species
Fully-Annotated Soundscape Recordings from Hawaii

635 recordings with 59,583 bounding boxes on 27 bird species
Fully-Annotated Soundscape Recordings from coffee farms in Colombia and Costa Rica

34 hour-long recordings with 6,952 bounding boxes on 89 bird species
Annotated Soundscape Recordings from western Kenya

35 soundscapes (32 hours total) with 10,294 labels for 176 bird species
An annotated set of audio recordings of Eastern NA birds
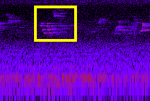
16,052 annotations on 48 species in 385 minutes

Several hundred thousand labeled audio clips of North American birds

>1M recordings of >10k species (mostly birds)
Xeno-canto data on GBIF: birds, bats, insects, soundscapes

93k recordings of frogs
Avian dawn chorus in CA, OR, and WA

~40k annotations on ~12 hours of audio for 118 sound types including 58 bird species
Watkins Marine Mammal Sounds (marine mammal recordings)

~15,000 high-quality excerpts from 32 marine mammal species, and additional lower-quality or unannotated data
Orcasound data (orca recordings)
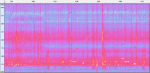
Annotated orca recordings

~50k recordings with species labels
27 hours of arctic soundscapes annotated with 28 classes
Unlabeled soundscapes from lowland rainforests in the Republic of Congo

570 vocalizations from 303 bird species in Uganda
Western Mediterranean Wetlands Bird Dataset

5,795 annotated audio clips from 1,098 Xeno Canto recordings

57,084 audio clips from coral reefs in 11 countries, with strong annotations
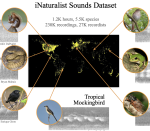
230k audio files for 5.5k species, collected via iNaturalist

~520k recordings from multiple datasets, harmonized into a consistent benchmark set

>1M song units from ~100k annotated songs
WABAD: World Annotated Bird Acoustic Dataset (paper)
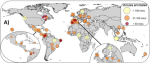
>90k boxed vocalizations for >1k bird species at 70 sites in 27 countries
NBM: an Open Dataset for the Acoustic Monitoring of Nocturnal Migratory Birds in Europe (paper)

>13k annotated vocalizations of nocturnal birds in Europe
A bunch of relevant competitions
Competitions are a great way to get started doing machine learning for environmental science, and each comes with a data set. Here are a few competitions that involve wildlife…
Competitions: terrestrial animal images
Conser-vision Practice Area (camera trap image classification)
Deep Chimpact (depth estimation for wildlife conservation)
Hakuna Ma-data (camera trap image classification)
Pri-matrix Factorization (individual chimp recognition)
iNaturalist computer vision competition (handheld photos of animals)
iWildCam (camera trap images)
Amur Tiger Re-identification in the Wild (individual ID for tigers from video)
NOAA Fisheries Steller Sea Lion Population Count (aerial images)
Snake Species ID Challenge (w/ ~100k images of ~4k snake species)
SnakeCLEF (snake images)
Cup-ybara (camera trap videos)
Competitions: marine/freshwater images
FathomNet 2025 (taxonomic classification in marine images)
N+1 fish, N+2 fish (fish detection and classification in ship-deck photos)
Where’s Whale-do? (individual whale identification)
Great Barrier Reef Crown of Thorns Detection (marine video with object labels on starfish)
NOAA Right Whale Recognition (aerial images)
Humpback Whale Identification (individual ID from fluke photos)
Nature Conservancy Fisheries Monitoring (species ID from ship-deck photos)
ImageCLEF coral (coral localization and identification in images)
SeaCLEF (marine animal identification in images and video)
Sea Turtle Face Detection (bounding box annotations on turtles)
Turtle Recall (individual ID)
FathomNet 2023 (species ID)
Competitions: plant images
Aerial Cactus Identification (cactus detection in aerial chips)
PlantCLEF (plant identification in images)
Competitions: geospatial images
Amazon Rainforest Challenge (deforestation monitoring from Landsat/Sentinel images)
Understanding the Amazon from Space (land cover from satellite images)
ICLR workshop challenge on crop detection from satellite imagery
Competitions: bioacoustics
Whale Detection Challenge (bioacoustics)
DCASE Bird Audio Detection challenge (bird detection from audio) (2018, 2021, 2022, 2023, 2024)
BirdCLEF (bird identification in audio) (2022, 2023, 2024, 2025)
Cornell Birdcall Identification (bird detection and identification from audio)
NIPS4B Multilabel Bird Species Classification (from audio)
Competitions: other
Random Walk of the Penguins (penguin population change prediction)
GeoLifeCLEF (species distribution estimation)
FungiCLEF (fungi images)
Other useful lists of conservation data sets
LILA datasets (just in case someone landed here and isn’t aware of the context… the page you’re looking at right now is a list of datasets that aren’t hosted on LILA)
Datasets with annotated wildlife in drone/aerial images
Wild Album (a data portal for CamtrapDP datasets on GBIF)
Other useful lists of open data sets
…that are relevant to environmental science, though maybe not directly focused on conservation.
Source Cooperative (formerly Radiant ML Hub)
Esri Living Atlas of the World
Microsoft Planetary Computer Data Catalog
Google Earth Engine Data Catalog
OpenForest (a list of open-access forestry data)
Other queries one might run to find conservation data sets
GBIF Datasets that use Camtrap DP
Kaggle dataset/competition search for “wildlife”
Kaggle dataset/competition search for “conservation”
Kaggle dataset/competition search for “animals”
Google Dataset Search for “wildlife”
Google Dataset Search for “conservation”
Google Dataset Search for “animals”
Posted by Dan Morris.