Overview
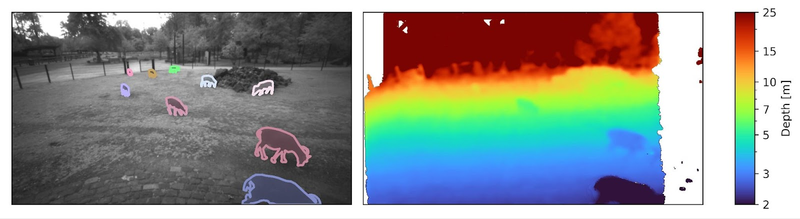
This data set contains 775 video sequences, captured in the wildlife park Lindenthal (Cologne, Germany) as part of the AMMOD project, using an Intel RealSense D435 stereo camera. In addition to color and infrared images, the D435 is able to infer the distance (or “depth”) to objects in the scene using stereo vision. Observed animals include various birds (at daytime) and mammals such as deer, goats, sheep, donkeys, and foxes (primarily at nighttime). A subset of 412 images is annotated with a total of 1038 individual animal annotations, including instance masks, bounding boxes, class labels, and corresponding track IDs to identify the same individual over the entire video.
Citation, license, and contact information
The capture process and dataset is described in more detail in the following preprint:
Haucke T, Steinhage V. Exploiting depth information for wildlife monitoring. arXiv preprint arXiv:2102.05607. 2021 Feb 10.
Please cite this manuscript if you use this data set. For questions about this data set, contact Timm Haucke at the University of Bonn.
This data set is released under the Community Data License Agreement (permissive variant).
Data format
The videos are captured using an Intel RealSense D435 stereo camera and stored as RealSense rosbag files. Each video contains intensity (RGB at daytime, IR at nighttime) and depth image streams with durations of 15 to 45 seconds at 15 frames per second. The depth images are computed on the RealSense D435 in real-time. Sequences recorded from December 17, 2020 additionally contain the raw left / right IR intensity images to facilitate offline stereo correspondence. The file names correspond to the local time, formatted as %Y%m%d%H%M%S.
A subset of videos is labeled with instance masks, bounding boxes, class labels, and track ids in the COCO JSON format. The first 20 frames of the video were skipped during annotation such that the annotated images are not affected by the automatic exposure process of the D435. After two seconds, every 10th frame was annotated with instance masks and track IDs. Together with the COCO JSON annotation files we provide the corresponding extracted still image files in JPEG (intensity) and OpenEXR (depth) format. The included Jupyter Notebook demonstrates how to load and visualize these images and the corresponding annotations.
Downloading the data
This dataset is provided as a single zipfile:
Download from GCP (213GB)
Download from AWS (213GB)
Download from Azure (213GB)
Having trouble downloading? Check out our FAQ.
Posted by Dan Morris.